Sprekende en luisterende computers
De kleine, teddybeerachtige wezens in de StarWars-film
Return of the Jedi zijn volstrekt onverstaanbaar. Luke
Skywalker roept de hulp in van de robot C-3PO. Die
vertaalt feilloos het gebrabbel, een opmerkelijke
demonstratie van taal- en spraaktechnologie die in de
werkelijkheid nog niet is geëvenaard. Allereerst
identificeert C-3PO de taal waarin Luke Skywalker hem
vraagt het gebrabbel te vertalen. Dan herkent hij de
woorden en begrijpt hij de inhoud van het verzoek.
Vervolgens doet hij hetzelfde voor de woorden in de
onbekende taal: taal identificeren, woorden herkennen
en betekenis begrijpen. Dan vertaalt hij het gebrabbel
in de taal van de vraagsteller en spreekt hij de
vertaalde mededelingen uit.
Spraakherkenning en spraaksysnthese zijn
voorbeelden van taal- en spraaktechnologie.
Uiteindelijk moeten deze technieken een vloeiend
gesprek tussen mens en machine mogelijk maken. Zo'n
systeem noemt men een gesprokendialoogsysteem. Denk
hierbij bijvoorbeeld aan Captain Kirk uit de film Star
Trek, die regelmatig met zijn boordcomputer praat.
Inmiddels zijn gesproken-dialoogsystemen, die
aanvankelijk alleen in science-fictionfilms voorkwamen,
werkelijkheid geworden.
Oplijning
De afdeling Taal en Spraak van de Katholieke
Universiteit Nijmegen werkt sinds enige tijd aan de
ontwikkeling van een gesprokendialoogsysteem voor het
Nederlands. Het Openbaar Vervoer Informatie Systeem is
de eerste concrete toepassing. Het informatiesysteem
verstrekt via de telefoon automatisch het grootste
gedeelte van de informatie die in het spoorboekje van
de Nederlandse Spoorwegen te vinden is. Je vraagt het
systeem naar vertrek- en aankomsttijden en de computer
antwoordt in duidelijk Nederlands.
Om een dialoog te kunnen voeren moet de computer
allereerst in staat zijn de gesproken vraag te
herkennen. Uiteraard herkent de computer alleen de
woorden die in zijn woordenboek staan. Het nieuwe
spraakherkenningssysteem van IBM, ViaVoice, beschikt
bijvoorbeeld, afhankelijk van de toepassing, over een
woordenschat tot ruim 128.000 woorden. Zo'n woordenboek
bevat van ieder woord twee vormen: ten eerste de
orthografische vorm, oftewel het woord zoals het wordt
geschreven, en ten tweede het woord zoals het wordt
uitgesproken. Dit is een reeks van foneemsymbolen, en
heet daarom een foneemtranscriptie. Ieder foneemsymbool
staat voor een bepaalde klank.
 |
 |
 |
(C) Natuur & Techniek
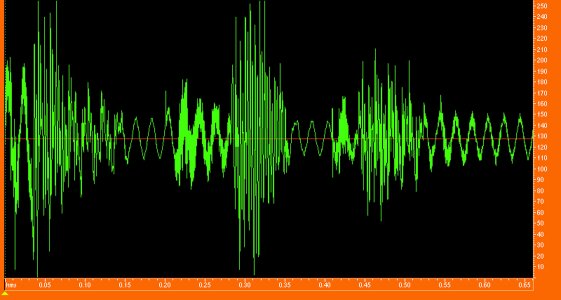
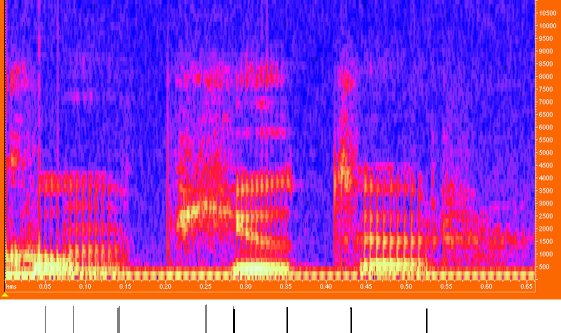
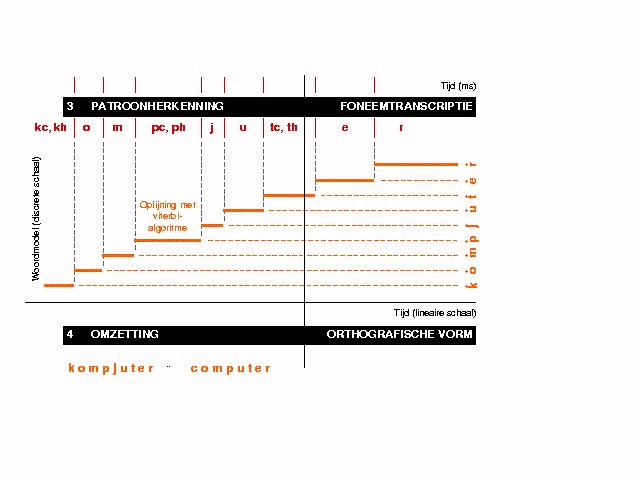
Figuur 1. Het proces van spraakherkenning grafisch
weergegeven.
Het proces van spraakherkenning grafisch weergegeven:
het woord computer'. Op de horizontale as staat steeds
de tijd, verticaal van boven naar beneden allereerst
het spraaksignaal, vervolgens een spectrale analyse,
waarbij paars via rood en oranje tot geel een
toenemende energie in het betreffende frequentiegebied
aangeeft, daaronder de foneeminterpretatie en onderaan
de orthografische interpretatie.
|
Aan de ingebruikname van een spraakherkenner gaat
een trainingsfase vooraf. In de trainingsfase maakt het
systeem kennis met een grote verzameling
spraakfragmenten, waarbij ieder fragment vergezeld gaat
van de bijbehorende tekst. Een dergelijke verzameling
heet een corpus. Het systeem zoekt bij alle fragmenten
uit het corpus de woorden in het woordenboek en
vervangt ieder woord door zijn foneemtranscriptie.
Vervolgens bepaalt het zogenaamde Viterbi-algoritme de
optimale oplijning tussen het spraaksignaal en de
foneemtranscriptie. Deze oplijning is in feite een
segmentering, die in het spraaksignaal de grenzen van
ieder van de elementen uit de foneemtranscriptie
bepaalt. Bovendien berekent het Viterbi-algoritme voor
de gevonden oplijning de kans dat het spraaksignaal en
de foneemtranscriptie bij elkaar horen. Het algoritme
kiest de oplijning met de grootste kans: de optimale
oplijning. In de trainingsfase worden het Viterbi-algoritme
en een trainingswoordenboek gebruikt om een
trainingscorpus geheel te segmenteren. Na segmentatie
kan voor iedere basiseenheid (foneem) worden opgezocht
welke stukken spraaksignaal uit het trainingscorpus
hierbij horen. Voor ieder foneem worden alle
bijbehorende stukken spraaksignaal statistisch verwerkt
en wordt een model berekend: een zogenaamd hidden
Markov model. Ieder aldus berekend akoestisch model is
een statistische beschrijving van alle bij dat foneem
behorende stukken spraaksignaal uit het
trainingscorpus.
Hypothesen
Voor succesvolle spraakherkenning zijn niet alleen
akoestische modellen nodig, maar ook taalmodellen. Het
huidige systeem gebruikt een unigram (de kans op ieder
woord) en een bigram (de kans op een woordpaar)
taalmodel. Deze taalmodellen worden getraind door in
het corpus te tellen hoe vaak ieder woord
respectievelijk iedere combinatie van twee woorden
voorkomt. Dit aantal gedeeld door het totaal aantal
woorden respectievelijk woordparen levert de kans
op.
In de herkenningsfase wordt tot slot geprobeerd een
onbekende uiting te herkennen. De spraakherkenner
genereert alle mogelijke opeenvolgingen van woorden.
Omdat van te voren niet bekend is uit hoeveel woorden
een zin bestaat, is het aantal hypothesen gigantisch
groot, zeker als de herkenner over een grote
woordenschat beschikt. Gelukkig scoort de
spraakherkenner alle hypothesen van begin af aan, dat
wil zeggen dat het bepaalt hoe waarschijnlijk iedere
hypothese is gegeven het binnenkomende (onbekende)
signaal. Hiervoor maakt het programma weer gebruik van
het Viterbi-algoritme, dat de optimale oplijning en de
bijbehorende kans bepaalt. Het merendeel van de
hypothesen blijkt dan al na een paar stappen zoveel
minder waarschijnlijk te zijn dan de favorieten, dat ze
zonder enig gevaar uit de lijst van mogelijke
oplossingen kunnen worden geschrapt. Op die manier
blijven geheugenbeslag en rekentijd voor het scoren van
de hypothesen binnen redelijke grenzen. Dit is
belangrijk omdat een spraakherkenner in de praktijk
real-time moet werken. Uiteindelijk valt de keuze op de
opeenvolging van woorden met de grootste kans zo
heeft de computer de aangeboden zin verstaan.
Opel Astra
Zodra de vraag verstaan is van spraak is omgezet in
tekst moet de computer de vraag interpreteren en er
een antwoord op verzinnen. Er bestaan vele
dialoogstrategieën om een computer een gesprek te laten
voeren. Een tijd lang was het bijvoorbeeld mogelijk dat
je in Nederland een automaat van de ANWB belde om de
waarde van je auto te bepalen. Een mogelijke dialoog
verloopt dan als volgt: "voor Opel toets 0, voor
Peugeot toets 1...," enzovoort. Nadat je een automerk
had gekozen, moest je het type en bouwjaar kiezen.
Hierbij doorliep je een vast menu, met op iedere plek
een beperkt aantal keuzen. In plaats van het intoetsen
van nummers zou ook spraak kunnen worden gebruikt:
"voor Opel zeg 0, voor Peugeot zeg 1...". Dergelijke
dialoogstructuren zijn in het begin daadwerkelijk
toegepast, omdat de beschikbare spraakherkenners alleen
de getallen 0 tot 9 konden herkennen. Iets natuurlijker
wordt het als je direct "Opel" of "Peugeot" kunt
zeggen, maar nog steeds moet je dan een vast menu
doorlopen.
Ofschoon je op deze manier tot de gewenste
informatie kunt komen, vinden veel bellers dit een
omslachtige en onnatuurlijke manier. Wat je het liefst
zou willen zeggen is: "Wat is de waarde van mijn Opel
Astra uit 1994?" In dat geval zul je een
dialoogstrategie moeten gebruiken die gemengd-initiatiefdialoog
genoemd wordt, omdat zowel het
systeem als de beller het initiatief kunnen nemen. Dit
is dus niet het geval bij een menugebaseerd systeem
waar het systeem altijd het initiatief neemt door
vragen te stellen waarop de beller alleen zeer
specifieke antwoorden kan geven. Het Openbaar Vervoer
Informatie Systeem voert een gemengd-initiatiefdialoog.
Krant
Zodra de computer het antwoord op de gestelde vraag
heeft geformuleerd, moet het nog worden uitgeproken. Er
is een aantal mogelijkheden om dit te doen. Welke
mogelijkheid wordt gekozen hangt af van de hoeveelheid
tekst in de applicatie. Als de hoeveelheid mededelingen
in een toepassing klein is, volstaat het terugspelen
van opgenomen boodschappen. Vijftien jaar geleden was
de afdeling Taal en Spraak van de Katholieke
Universiteit Nijmegen betrokken bij de ontwikkeling van
een sprekende lift, die (met name voor visueel
gehandicapten) belangrijke informatie uitspreekt, zoals
"de lift komt" en "u nadert de eerste verdieping". Deze
techniek wordt nu ook toegepast in speelgoed, zoals de
sprekende pop.
Het werken met opgenomen boodschappen is ondoenlijk
als de hoeveelheid tekst heel groot is. In dat geval
biedt de zogenaamde spraaksynthese uitkomst. Een mooi
voorbeeld is de elektronisch leesbare krant. Zo
verstrekt het Centrum voor Gesproken Lektuur in Grave
voor visueel gehandicapten elektronische versies van
kranten. De gebruiker haalt via de telefoonlijn de
digitale versie op de eigen computer binnen. Via
speciale software en spraaksynthese kan hij vervolgens
de krant beluisteren.
 |
(C) Natuur & Techniek
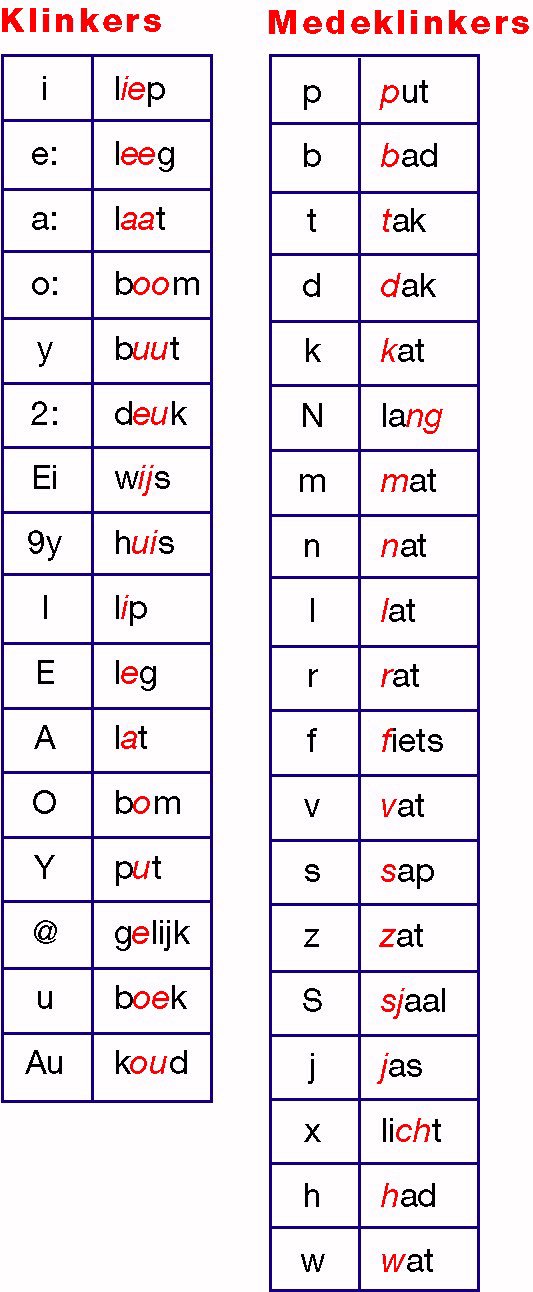
Tabel 1. Fonemen.
Fonemen, of spraakklanken, zijn de bouwstenen van de
spraak. OVIS is getraind in bovenstaande 35 fonemen.
Links steeds de foneem, rechts een voorbeeld van een
woord waarin de klank voorkomt. |
Bij spraaksynthese wordt de binnenkomende tekst,
een reeks van letters, allereerst omgezet in een reeks
van foneemsymbolen (klanktekens, zie pagina 14). In het
woord rekenwerk' bijvoorbeeld zitten drie
verschillende klanken e', die dus elk met een ander
foneem moeten worden beschreven. Vervolgens wordt de
reeks fonemen omgezet in een spraaksignaal. Ofschoon
deze spraak (zeker na enige gewenning) goed
verstaanbaar is, valt het meteen op dat het geen
menselijke spraak is maar een computerstem. In de
meeste commerciële applicaties geeft men nog de
voorkeur aan een meer natuurlijk klinkende stem, zo ook
voor het verstrekken van reisinformatie door het
Openbaar Vervoer Informatie Systeem (OVIS).
Zelfs het beperkte aantal mededelingen dat OVIS moet
uitspreken, is al te groot om allemaal apart op te
nemen. Het terugspelen van een volledige verzameling
opgenomen boodschappen is dan onmogelijk. Denk hierbij
aan het grote aantal combinaties van stations en
reistijden. De lijsten van afzonderlijke onderdelen
(stationsnamen, dagen, data en tijdstippen) is echter
te overzien en kan wel van tevoren worden opgenomen.
Dit is bij OVIS gebeurd. Naar gelang de informatie die
de gebruiker nodig heeft, plakt het systeem simpelweg
spraakfragmenten aan elkaar vast. Deze techniek noemt
men spraakconcatenatie. Het nadeel van deze techniek is
natuurlijk dat als je woorden wilt toevoegen je deze
eerst moet opnemen.
PIN-code
Een populaire toepassing van
spraakherkenningstechnologie is de dicteersoftware. Wie
niet op spreektempo kan typen, kan met zulke
programmatuur enorme tijdwinst boeken. Een andere
toepassing is het handenvrij telefoneren. Onlangs
stelde een Nederlandse politieke partij voor om
telefoneren in de auto alleen toe te staan als deze
techniek wordt gebruikt. Zonder de handen van het stuur
te nemen vertel je de telefoon wie je wilt bellen de
spraakherkenning in de telefoon doet de rest.
Voor toepassingen in bijvoorbeeld beveiliging is
alleen het herkennen van gesproken tekst niet
voldoende. De identiteit van de spreker moet ook op
basis van zijn spraak worden vastgesteld. Een
toepassing die binnenkort zeker gebruikt gaat worden,
is telefonisch thuisbankieren. De klant noemt zijn
rekeningnummer en pincode, de spraakherkenner herkent
dit, weet dan wiens rekening het betreft en controleert
of de spraak die van de rekeninghouder is. Een andere
toepassing van spraakherkenning en sprekerverificatie
is stemgestuurde toegangscontrole: de deur van een
ruimte gaat alleen open als de juiste persoon de juiste
boodschap uitspreekt.
Bij Openbaar Vervoer Reisinformatie is het
OVIS gesproken-dialoogsysteem al operationeel en talrijke
andere toepassingen zullen spoedig volgen. In de
toekomst zal het steeds vaker gebeuren dat je niet
alleen tussen neus en lippen door iets tegen een
machine zegt, maar dat hij je ook nog eens begrijpt.
Auteur
Dr Helmer Strik (41) studeerde natuurkunde aan de
Katholieke Universiteit Nijmegen en promoveerde in 1994
aan dezelfde universiteit. Op de afdeling Taal & Spraak
van deze universiteit verzorgt hij een aantal colleges
in het kader van de opleidingen Taal, Spraak &
Informatica (TSI) en Spraak- & Taalpathologie (STP).
Hij doet onderzoek in het kader van verschillende
Europese projecten en een post-doctoraal project van de
Koninklijke Nederlandse Akademie van Wetenschappen.
Literatuur
- Markowitz JA. Using speech recognition. New Jersey:
Prentice-Hall Inc., 1996.
- Rabiner LR, Juang B-H. Fundamentals of speech
recognition. New Jersey: Prentice-Hall Inc., 1993.
- Schmandt C. Voice communication with computers. New
York: Van Nostrand Reinhold, 1994.
- Van Santen JPH, Sproat RW, Olive JP, Hirschberg J.
Progress in speech synthesis. New York: Springer-Verlag, 1996.
Computerspraak op internet
Appendix 1: Praten met een computer
Reizigers met het openbaar vervoer kunnen voor vertrek-
en aankomsttijden bij een informatienummer terecht. Wie
wil, kan zich daarbij door een computer te woord laten
staan.
Wie in Nederland Openbaar Vervoer Reisinformatie belt
(0900 9292) krijgt meestal een telefonist(e) van vlees
en bloed aan de lijn. Van middernacht tot 6 uur s
ochtends en bij wachttijden van meer dan 30 seconden
wordt de beller door een computer met spraakherkenning
te woord gestaan: het Openbaar Vervoer Informatie
Systeem (OVIS). Van de 30.000 tot 35.000 telefoontjes
die Openbaar Vervoer Reisinformatie dagelijks te
verwerken krijgt, worden er momenteel zo'n 3500 door de
computer afgehandeld.
Systeem: "Van welk station naar welk station wilt
u reizen?"
De openingszin is belangrijk. Zou het systeem gewoon
"goedemorgen" zeggen, dan zijn mensen geneigd om
allerlei lange verhalen te gaan vertellen. Als de
dialoog daarentegen begint met een gerichte vraag,
geven de bellers vaker een bondig antwoord zoals
bijvoorbeeld:
Gebruiker: "Ik wil morgen van Maarn naar
Amsterdam."
De spraakherkenner zet het spraaksignaal om in een
woordreeks. De natuurlijke-taalverwerkingsmodule zoekt
naar concepten in de herkende woorden. In dit geval
vindt hij de concepten morgen', Maarn' en
Amsterdam'. De dialoogcontrolemodule slaat deze
informatie op en kijkt of er nog iets ontbreekt. In dit
geval ontbreekt het tijdstip van vertrek of van
aankomst. Omdat de door de beller gegeven informatie
nog niet compleet is, moet het systeem om aanvullende
gegevens vragen. De dialoogcontrolemodule formuleert de
vraag (in tekstvorm). De spraakgenerator zet deze vraag
(tekst) om in spraak. Deze gesproken vraag wordt via de
telefoon naar de gebruiker gestuurd.
Systeem: "Hoe laat wilt u morgen van Maarn naar
Amsterdam reizen?"
Gebruiker: "Ik wil morgenavond om acht uur
vertrekken."
De spraakherkenner herkent weer de woorden en de
natuurlijke-taalverwerkingsmodule zoekt naar concepten.
In dit geval morgenavond' en om 8 uur'. Ofschoon
eerder al morgen' herkend was, is het concept
morgenavond' toch nog belangrijk, namelijk om te weten
of de gebruiker om 8 uur 's morgens of 's avonds wil
vertrekken. De dialoogcontrolemodule ziet dat de vraag
nu compleet gespecificeerd is, zoekt het antwoord op in
het gegevensbestand en formuleert het antwoord (in
tekstvorm). De spraakgenerator zet het antwoord weer om
in klanken, die via de telefoon naar de gebruiker
worden gestuurd. Tenslotte vraagt het systeem of de
gebruiker nog andere informatie wil. Als de gebruiker
ontkennend antwoordt, bedankt het systeem voor het
gebruik en verbreekt het de verbinding.
|
Intermezzo: Sprekerverificatie
Automatische sprekerverificatie is het door een
computer verifiëren van de identiteit van een persoon
aan de hand van zijn of haar stemkarakteristieken. Net
zoals mensen moet de computer eerst iemands stem leren
kennen voordat hij de stem kan herkennen. Tijdens het
kennismakingsproces legt de computer de
stemkarakteristieken vast in een sprekermodel op basis
van een ingesproken tekst. Het model dat de beste
prestaties levert bij spraakherkenning, namelijk het
statistische hidden Markov model, werkt ook het beste
bij sprekerverificatie. Bij sprekerverificatie wordt
iedere stemkarakteristiek beschreven door een
gemiddelde en een variantie.
Is er eenmaal zo'n model, dan is de computer in
staat de stem te herkennen. In de herkenningfase claimt
een onbekende persoon X de identiteit van A (door
bijvoorbeeld zijn rekeningnummer of pin-code te
noemen). De computer vergelijkt de spraak van X met het
sprekermodel van A en het automatische
sprekerverificatiealgoritme geeft dan als output: met
een kans van p procent is persoon X dezelfde als A.
Omdat de herkenner nooit 100% zeker is moet dan nog
een drempelwaarde gekozen worden: bijvoorbeeld als de p
groter is dan 80% dan beslist het systeem dat X
dezelfde moet zijn als A. Verhogen we de drempelwaarde
dan wordt het systeem meer inbraakbestendig, maar
tegelijkertijd wordt de kans groter dat gebruikers
onterecht worden geweigerd. De instelling van de
drempelwaarde wordt grotendeels bepaald door de aard
van de toepassing, maar de instelling zou bijvoorbeeld
zo kunnen worden gekozen dat het percentage
herkenningsfouten wordt geminimaliseerd. In testversies
waar sprekerverificatie gebeurt met cijferreeksen
(zoals rekeningnummers), is gebleken dat een
foutenpercentage van minder dan 3% mogelijk is.
Blijkbaar zijn stemkarakteristieken uniek genoeg om
in een overtuigende meerderheid van de gevallen een
correcte uitspraak te doen over de identiteit van een
spreker. Wie het zelf eens wil proberen kan terecht op
de spraak-beveiligde internetsite van de afdeling Taal
en Spraak van de Katholieke Universiteit Nijmegen:
http://lands.let.kun.nl/TSpublic/cave.
Ir Johan Koolwaaij is verbonden aan de afdeling Taal &
Spraak van de Katholieke Universiteit Nijmegen
|
Bijschriften bij niet afgebeelde figuren
- Met de knieën sturend een rotonde nemen hoeft niet
meer: de handen kunnen voortaan aan het stuur blijven
tijdens het telefoneren. Noem het nummer of de naam van
degene die gebeld moet worden en de telefoon kiest zelf
het nummer communiceren zonder dat je een toets hoeft
aan te raken.
- De Siemens Voice Engine. Op deze chip is de elektronica
voor de herkenning, opslag en weergave van spraak
ge‹ntegreerd.
- BMW wil nog dit jaar spraakherkenning in de auto
leveren. De bestuurder kan het navigatiesysteem
mondeling de bestemming opgeven. Niet alleen via het
beeldscherm maar ook middels spraaksynthese wijst het
navigatiesysteem de bestuurder dan de weg. Een aan de
spraakherkenning gekoppelde telefoon die automatisch
het gewenste nummer kiest vraagt minder aandacht van de
bestuurder.
- De geldautomaat vraagt in de toekomst niet alleen een
PIN-code, maar ook een spraakfragment alvorens tot
uitbetaling te besluiten.
- De Nederlandse firma Libertel is een van de bedrijven
die spraakherkenningstechnologie toepast. Noem het
nummer en het wordt gekozen. De spraakherkenning vindt
plaats in de centrale, en niet in de telefoon.
British Telecom experimenteert met een Talking head: de
computer synthetiseert niet alleen de spraak, maar
voorziet de spraak ook van een bijbehorend hoofd. De
lippen bewegen synchroon met de woorden mee.
| Authors: |
H. Strik & J.W. Koolwaaij |
| Reference: |
Natuur & Techniek, Natuurwetenschappelijk & Technisch maandblad, 66e jaargang, nr. 9, sept. 1998, pp. 10-19. |